¿Qué es RAG?
En esta serie de publicaciones en el blog, compartiré los problemas que enfrentamos al desarrollar un sistema RAG. Antes de adentrarnos en los inconvenientes, echemos un breve vistazo general a qué es RAG.
Todo comenzó con un proyecto. El objetivo del proyecto era crear un chatbot para distintas empresas. Cada empresa sube sus archivos a una plataforma donde sus empleados pueden interactuar con ellos a través del chat. Un ejemplo podría ser un hospital. Supongamos que un empleado no recuerda un protocolo específico. Lo que haría normalmente es: ir al archivo, buscar entre miles de documentos el protocolo adecuado y tratar de encontrar EL indicado. En cambio, lo que propusimos fue "chatear con los protocolos". Así, el empleado accede al chatbot y pregunta: "¿Qué protocolo habla sobre X?" y el chatbot le proporciona el protocolo correcto. Facilísimo, rápido y sencillo. Desde una perspectiva técnica, este proyecto implementa básicamente RAG (Retrieval-Augmented Generation).
Si ya estás familiarizado con RAG y cómo funciona, puedes saltarte esta publicación. Pero si quieres refrescar la memoria, sigue leyendo. Intentaré explicarlo de la forma más simple y clara posible. De hecho, antes de darte una definición formal, voy a explicarte el objetivo de RAG con un ejemplo.
¿Qué es el RAG?
Todos conocemos cómo funcionan los motores de búsqueda, como Google: escribes una pregunta, el motor de búsqueda explora Internet, encuentra contenido relevante y luego te muestra una lista de resultados para que los revises. Como usuario, eres tú quien tiene que deducir la respuesta a partir de esa lista. Un Modelo de Lenguaje (LLM) realiza una tarea inicial similar, pero en lugar de solo mostrar contenido, combina y sintetiza la información para generar directamente una respuesta.

Tanto el motor de búsqueda como el LLM "buscan" en Internet. Para ser más precisos, el motor de búsqueda lo hace en tiempo real, mientras que el LLM ha sido entrenado con datos provenientes de Internet. Pero ¿cómo podemos crear esta experiencia con contenido que no está disponible en línea? La solución es RAG. RAG es un método que mejora la precisión y relevancia de las respuestas de un LLM al integrar datos externos. Funciona en dos pasos: recuperación y generación. El primer paso consiste en buscar en una base de datos específica los documentos relacionados con la pregunta (paso de recuperación) y luego usar esa información para generar una respuesta (paso de generación). Esta fue una explicación resumida y compacta. Si quieres profundizar más, hay muchos artículos que explican RAG con mayor detalle.
Pasos para implementar RAG
¿Y cómo se ve esto en la práctica? En nuestro caso, queremos generar un chatbot con el conocimiento contenido en PDFs, y usamos RAG para asegurarnos de que las respuestas provengan de nuestros propios PDFs y no de sitios web aleatorios. Estos fueron los pasos que seguimos para implementarlo:
- Parsear los PDFs a texto
- Proceso de segmentación (Chunking):
- Utilizar chunking para dividir los PDFs en fragmentos más pequeños.
- Agrupar los tokens (palabras) en unidades más grandes y significativas llamadas chunks.
- Usar el Recursive Text Splitter de LangChain con:
- Tamaño de chunk: 1000 caracteres
- Superposición entre chunks: 200 caracteres
- Divisores: párrafos, líneas, palabras y caracteres
Explicación breve del Recursive Text Splitter: Primero, divide el texto por párrafos (\n\n) y cuenta los caracteres. Si el párrafo supera los 1000 caracteres, lo divide por líneas (\n), y si aún es necesario, por palabras. Luego, va uniendo palabras hasta que el chunk tenga menos de 1000 caracteres, asegurándose de que la superposición entre chunks no exceda los 200 caracteres. Por último, también puede unir párrafos si no superan los 1000 caracteres.
- Convertir cada chunk en un vector de embedding de 1536 dimensiones.
- Almacenar los embeddings en una base de datos vectorial (en nuestro caso, Qdrant).
- Cuando un usuario hace una pregunta:
- Convertir la pregunta en un vector de embedding.
- Realizar una búsqueda de embeddings para comparar el embedding de la pregunta con los embeddings de los chunks. Esta búsqueda usa cosine similarity para encontrar los 100 chunks con mayor puntuación.
- Usar un modelo cross-encoder para asignar puntuaciones de relevancia a los chunks. El modelo compara cada par pregunta-chunk y asigna una puntuación basada en el contexto y la semántica. Luego, reordena los chunks con puntuaciones iguales o superiores a 0.05 según esa relevancia.
- Seleccionar los 5 chunks más relevantes, que representarán nuestro contexto.
- Crear un prompt bien estructurado usando la pregunta del usuario y los chunks seleccionados.
- Generar la respuesta alimentando ese prompt a un LLM como ChatGPT o Claude.
Y aquí tienes un esquema de todo este proceso:
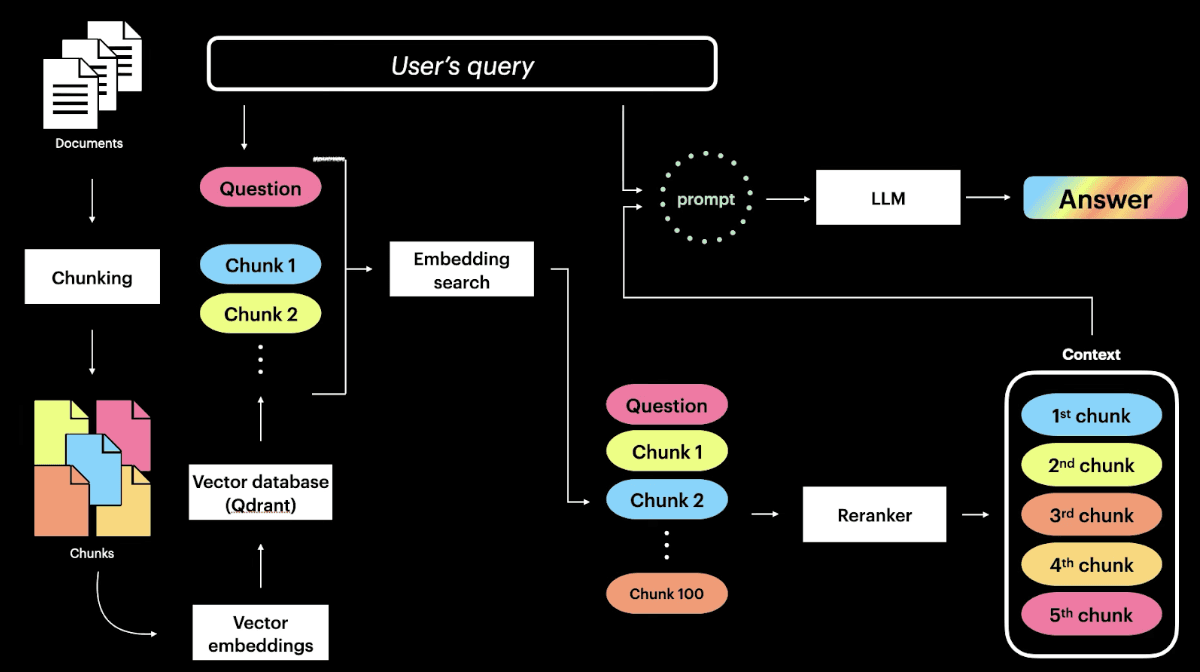
¿¿Confundido?? Cuando vi esto por primera vez, me tomó días entender a fondo cada paso. Después de comprender esta relación complicada, mis compañeros vinieron a mí y dijeron: "Queremos que mejores este RAG", y desde entonces he estado intentando hacerlo.
Spoiler: el chatbot no estaba funcionando bien. Así que mi tarea se convirtió en "hacer que funcione".
Nota importante: "No estaba funcionando" significa que el LLM alucinaba. Porque tenemos a los desarrolladores más cracks de Borah (😏), la parte de frontend/backend estaba perfecta.
Así es como empezaron mis problemas, y en las siguientes publicaciones voy a repasar todos los inconvenientes que enfrentamos.
Spoiler: El problema principal es extraer el texto de los documentos de una forma adecuada y usar el lenguaje de los propios documentos. Como nuestros clientes son españoles, los documentos también lo son. Y todas las herramientas que encontré online (probé montones) no funcionan bien en nuestro caso, porque la mayoría no son multilingües y están pensadas para textos en inglés. Me refiero a herramientas como extractores de PDFs, buscadores de embeddings o modelos de re-rankeo.
Antes de terminar este post, quiero explicar brevemente qué significa que un LLM "alucine", por si acaso el lector no lo sabe. ¡Y si ya lo sabes, eres más que bienvenido a saltar al siguiente post!
¿Qué son las alucinaciones de los LLM?
Muy brevemente, los LLMs a veces pueden generar información que suena convincente, pero que en realidad es incorrecta. A eso se le llama alucinaciones. Estas pueden clasificarse en tres tipos:
🔹 Alucinación en conflicto con la entrada: Ocurre cuando el LLM genera contenido que contradice o se desvía de la información que proporcionó el usuario. Por ejemplo:
Usuario: Necesito una receta para una cena saludable esta noche. ¿Puedes sugerirme algo? Modelo: ¿Qué tal una deliciosa ensalada de pollo a la parrilla para el almuerzo? Es una opción ligera y refrescante para tu comida del mediodía. 😵💫
🔹 Alucinación en conflicto con el contexto: Aquí, el LLM genera contenido que contradice algo que él mismo dijo antes, creando inconsistencias internas. Por ejemplo:
Usuario: Cuéntame cuál es tu libro favorito. Modelo: Mi libro favorito es Matar a un ruiseñor. Es una gran novela de ciencia ficción sobre la exploración espacial. 😵💫
🔹 Alucinación en conflicto con los hechos: Simplemente, el modelo se equivoca. Por ejemplo:
Usuario: ¿Cuál es la capital de Italia? Modelo: La capital de Italia es Madrid. 😵💫😵💫
Además, los LLMs están entrenados con datos hasta cierta fecha (tienen un punto de corte), lo que significa que no conocen información actual. Esto puede llevar a respuestas desactualizadas. Por ejemplo, si preguntas por el último modelo de iPhone, un LLM con corte en 2023 podría decir que el iPhone 15 es el más nuevo, aunque ya hayan salido modelos más recientes.
¿Y ahora qué?
Esta fue una explicación breve sobre las alucinaciones. Si te interesa conocer todos los problemas que enfrentamos al implementar RAG y cómo los resolvimos, te invitamos a seguir leyendo nuestras próximas publicaciones sobre este tema.
Referencias: