8 abr 2025
·
Tamara Orlich
What is RAG
In this series of blog posts, I will share the issues we faced while developing a RAG system. Before diving into the problems, let’s first have a brief overview of RAG.
Everything started with a project. The project aimed to create a chatbot for different companies. Each company uploads their files to a platform where workers can chat with them. An example could be a hospital. Let’s say that an employee doesn't remember a specific protocol. What they would do is: go to the archive, search for the proper protocol in the middle of thousands of documents and try to find THE one. Instead, what we proposed is to “chat with the protocols”. So the employee navigates to the chatbot and asks, “What protocol talks about X?” and the chatbot provides the correct protocol to the employee. Easy peasy, fast and easy. So, from a technical perspective, this project basically implements RAG (Retrieval-Augmented Generation).
Feel free to skip this blog post if you are already familiar with RAG and how it works. If you want to refresh your memory, keep reading. I will try to make it as simple and easy to understand as possible. Actually, before giving you a formal definition, I will explain the aim of RAG with an example.
What is RAG?
We all know how search engines, like Google, work: you type a question, the search engine searches through the Internet, finds relevant content and then lists that content for you to review. As a user, you have to figure out the answer from the results list. A Large Language Model (LLM) performs a similar initial task, but instead of just listing the content, it combines and synthesises the information to generate the answer directly.

The search engine and the LLM “search” through the Internet. To be more precise, the search engine searches through the internet, while the LLM is trained on data that comes from the Internet. But how can we create this experience with content that isn't available online? The solution is RAG. RAG is a method that improves the accuracy and relevance of LLM outputs by integrating external data. RAG works in two steps: retrieval and generation. The first step is to search through a specific database to find documents related to the question (retrieval step) and then to use the retrieved information to generate a response (generation step). So, this was a squished/short explanation. If you want to know more about RAG, tons of articles explain it in more detail.
RAG Implementation Steps
And what does this look like in practice? In our case, we want to generate a chatbot with the knowledge of pdfs, and we use RAG to ensure that the answers come from our pdfs and not random websites. This was our step-by-step implementation:
Parse the PDFs into text
Chunking Process:
Use chunking to break down the PDFs into smaller pieces.
Group tokens (words) into larger, meaningful units called chunks.
Use the Recursive Text Splitter from LangChain with chunk size (1000 characters), chunk overlap (200 characters) and the splitters: paragraph, lines, word and character. (Short explanation of how the Recursive Text splitter works. First, the recursive text splitter splits the text by paragraph (\n\n) and counts the characters. If the paragraph exceeds 1000 characters, it splits the paragraph by lines (\n) and later, if necessary, by words. Then, it merges the words until the number of characters is less than 1000, ensuring that the chunk overlap does not exceed 200 characters. Finally, it also merges the paragraphs if they do not exceed 1000 characters.)
Convert each chunk into a 1536-dimensional vector embedding.
Store embeddings in a vector database (in our case, Qdrant).
When a user asks a question, convert the question into a vector embedding.
Perform an embedding search to compare the question’s vector embedding with chunk embeddings. Embedding search uses cosine similarity to find the top 100 chunks with the highest scores.
Use a cross-encoder model to assign relevance scores to the chunks. The cross-encoder model compares each query-chunk pair and assigns a relevance score based on context and semantics. Then, it reorders the chunks with scores greater than or equal to 0.05 based on the relevance score.
Select the top 5 chunks which represent our context.
Create a well-structured prompt using the user’s question and the selected chunks.
To generate the answer, provide the prompt to an LLM, like ChatGPT or Claude.
And here you have a schema of this process:
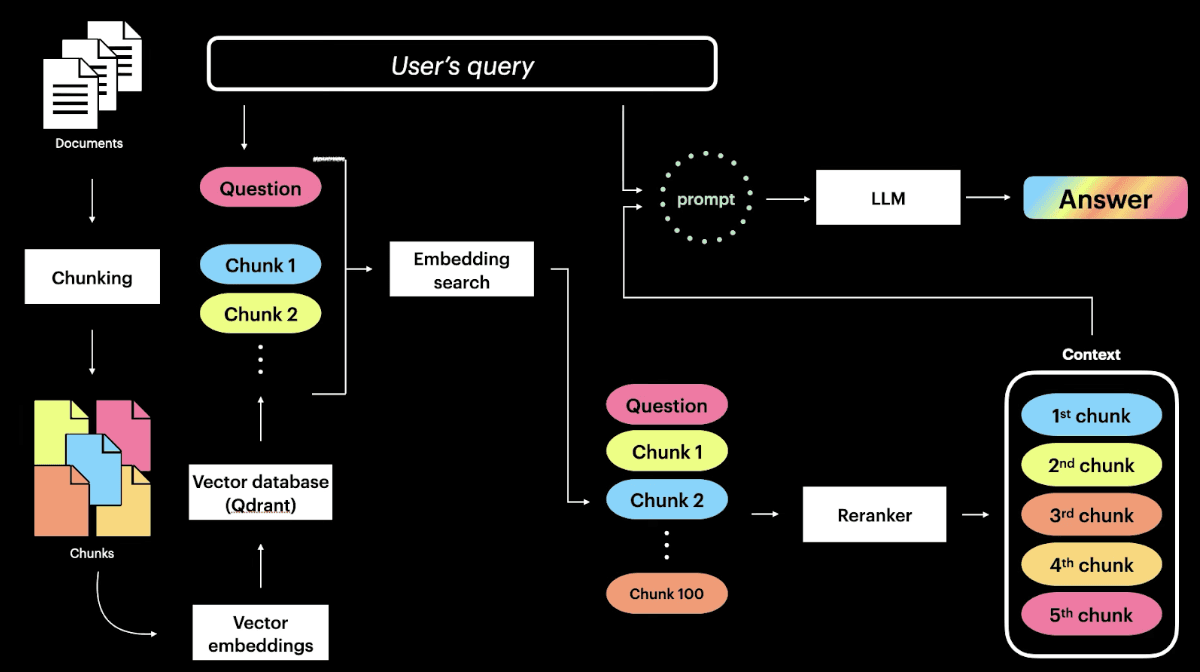
Confused? When I first saw this, it took me days to thoroughly understand each step. After understanding this situationship, my coworkers came to me and said, “We want you to improve this RAG,” which I've been trying to do since then.
Spoiler: the chatbot wasn’t working well. So my task became to “make it work”.
Important Note: “It wasn’t working” means the LLM hallucinated. Because we have the most outstanding developers in Borah (😏), the frontend/backend part was excellent.
So, this is how my problems started, and in the following posts, I will go through all of the issues we faced.
Spoiler: The main problem is extracting the text from the documents in a nice way and using the language of the documents. Since our clients are Spanish, so are the documents. So, all the tools I found online (I checked tons of them) don't work in our case because most are not multilingual and are for English texts. I’m talking about tools like PDF parsers, embedding search, or re-rankers.
Before concluding this post, I just want to briefly explain what “LLM is hallucinating” means, just in case you, the reader, don’t know. If you already know, then you are more than welcome to jump to the next blog post!
What are LLM Hallucinations?
So briefly, LLMs can sometimes generate information that sounds legit, but in reality, they are incorrect. These are known as hallucinations. They can be classified into three types:
Input-conflicting hallucination: occurs when LLMs generate content that contradicts or deviates from the information provided by users. For example:
User: I need a recipe for a healthy dinner tonight. Can you suggest something?
Model: How about a delicious grilled chicken salad for lunch? It's a light and refreshing option for your midday meal. 😵💫
Context-conflicting hallucination: in this case, LLMs generate content that conflicts with the information previously generated by itself, leading to inconsistencies within the generated context. For example:
User: Tell me about your favourite book.
Model: My favourite book is 'To Kill a Mockingbird'. It's a great science fiction novel about space exploration.😵💫
Fact-conflicting hallucination: when the LLM just get the things wrong, like:
User: What is the capital of Italy?
Model: The capital of Italy is Madrid.😵💫😵💫
Also, LLMs are trained on data up to a certain cutoff point; they are time-frozen. And this can lead to outdated responses. For example, if you ask about the latest iPhone model, an LLM with a 2023 cutoff might still think the iPhone 15 is the newest, even though Apple has released new models since then.
What’s next?
That was a short explanation of hallucinations. If you are interested in all the problems we faced while implementing RAG and how we solved them, you are welcome to read our next posts on this topic.
References
https://research.ibm.com/blog/retrieval-augmented-generation-RAG
https://vectorshift.ai/blog/what-are-llm-hallucinations-and-how-to-avoid-them