Tu conocimiento empresarial, accesible en segundos con RAG enterprise
Diseñamos y desarrollamos una plataforma de Retrieval-Augmented Generation para empresas que necesitan consultar su propia documentación con precisión, contexto y control total.
Cliente
Producto propio
Duración
En desarrollo continuo
Rol
Concepto, diseño, desarrollo e infra
El producto
Plataforma RAG Enterprise
La mayoría de empresas acumula conocimiento en documentos que nadie consulta de forma eficiente. PDFs internos, manuales, hojas de cálculo, presentaciones, URLs, incluso vídeos. La información existe, pero llegar a ella requiere tiempo, contexto y saber dónde buscar.
Las herramientas genéricas de IA no resuelven este problema. No entienden el contexto empresarial, no controlan qué información procesan, y en español, su precisión cae.
El reto
Conocimiento disperso, herramientas que no lo entienden
Las empresas dependían de búsquedas manuales o herramientas como ChatGPT para consultar su documentación. El resultado: respuestas sin contexto, información desactualizada y cero control sobre qué datos se procesan.
Las consecuencias eran claras. Horas perdidas buscando lo que ya existía. Decisiones tomadas con información incompleta. Conocimiento que se perdía cuando alguien dejaba la empresa. Y ninguna herramienta del mercado combinaba soporte real en español, múltiples fuentes de datos y control empresarial sobre la ingesta.
La plataforma
Lo que construimos
Una plataforma completa para que las empresas consulten su conocimiento interno con precisión y control.
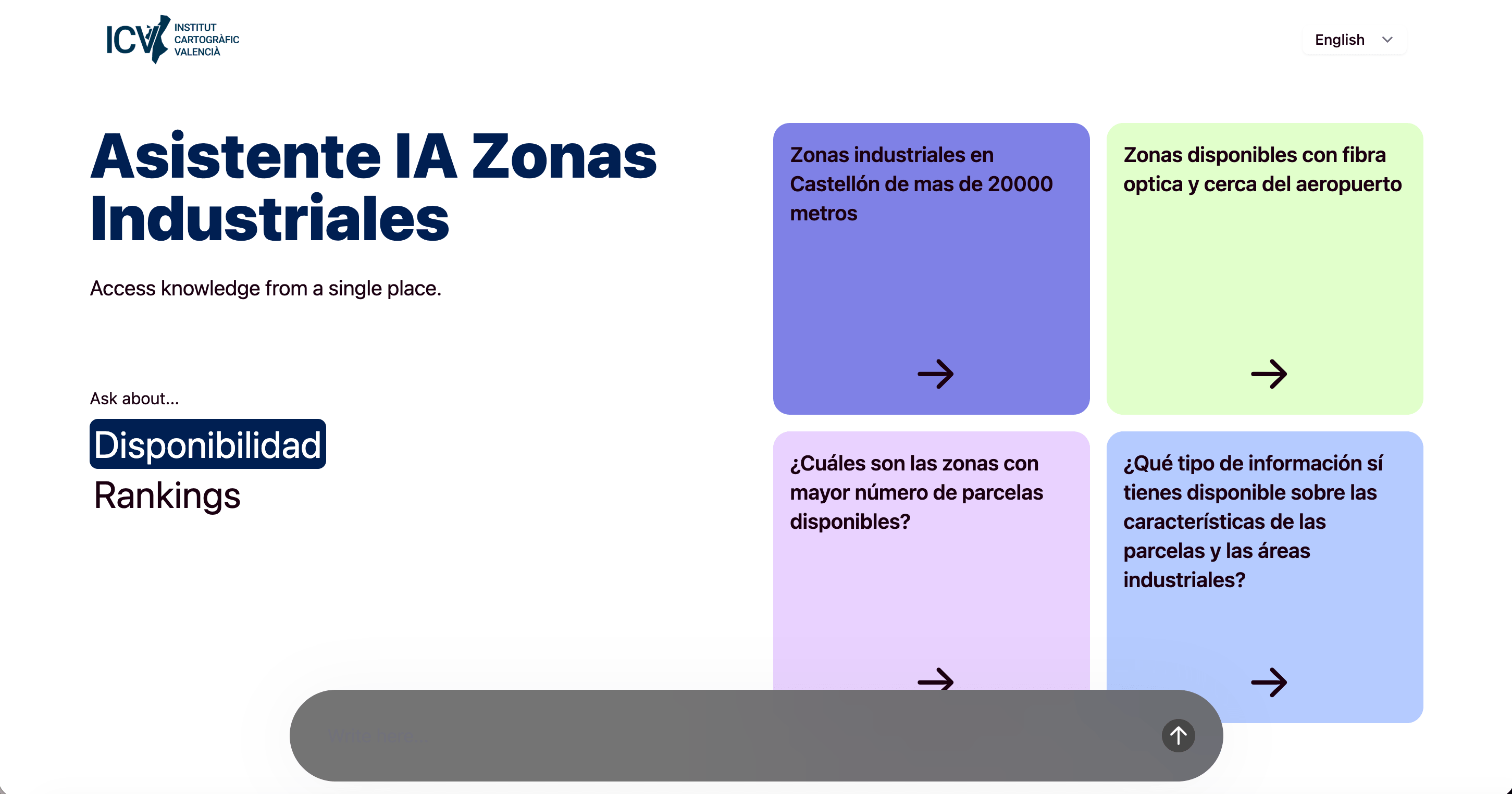
Interfaz de consulta
Consulta la base documental de tu empresa en lenguaje natural
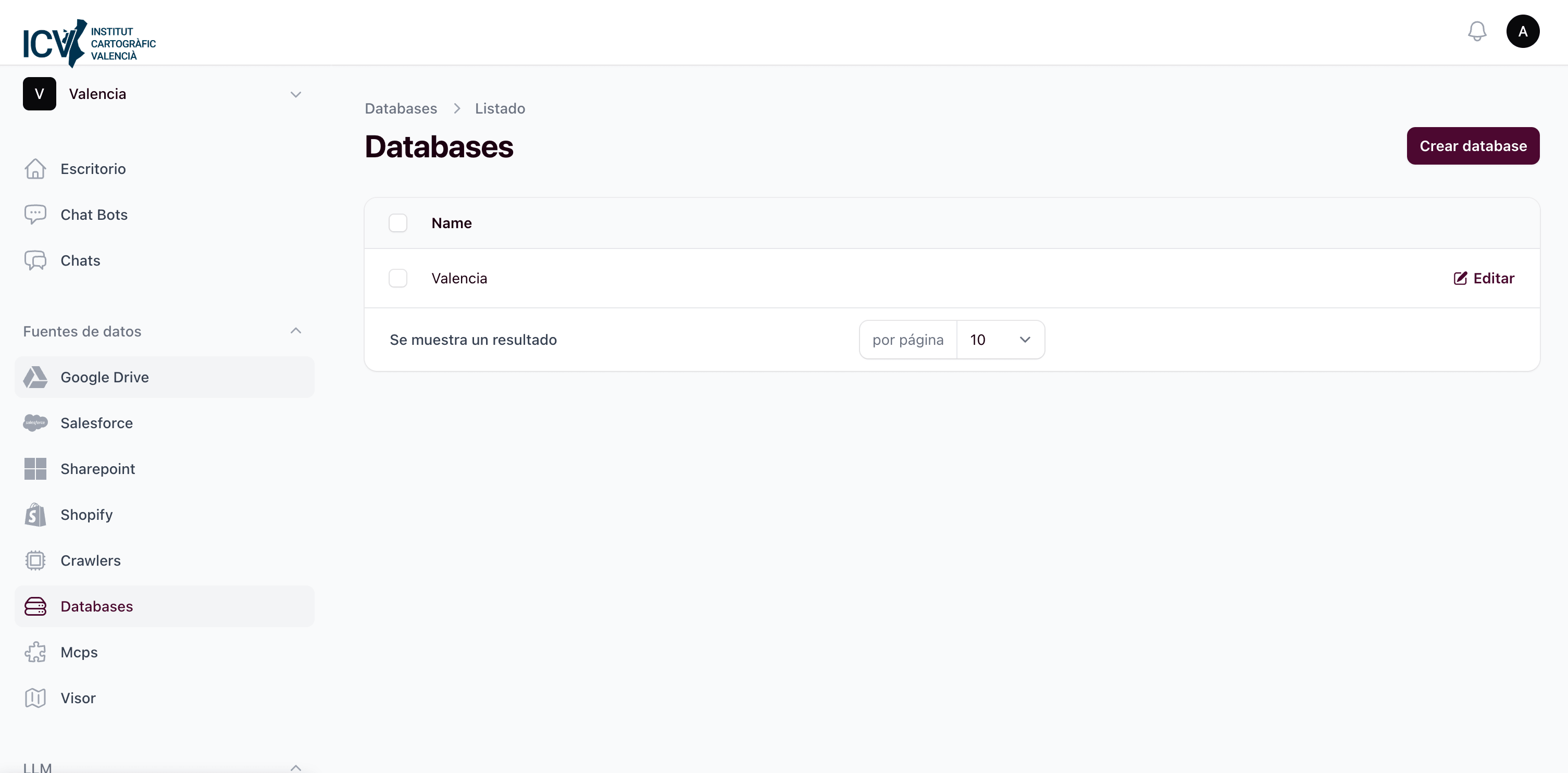
Panel de ingestión
Gestión de fuentes de datos con guardrails de calidad integrados
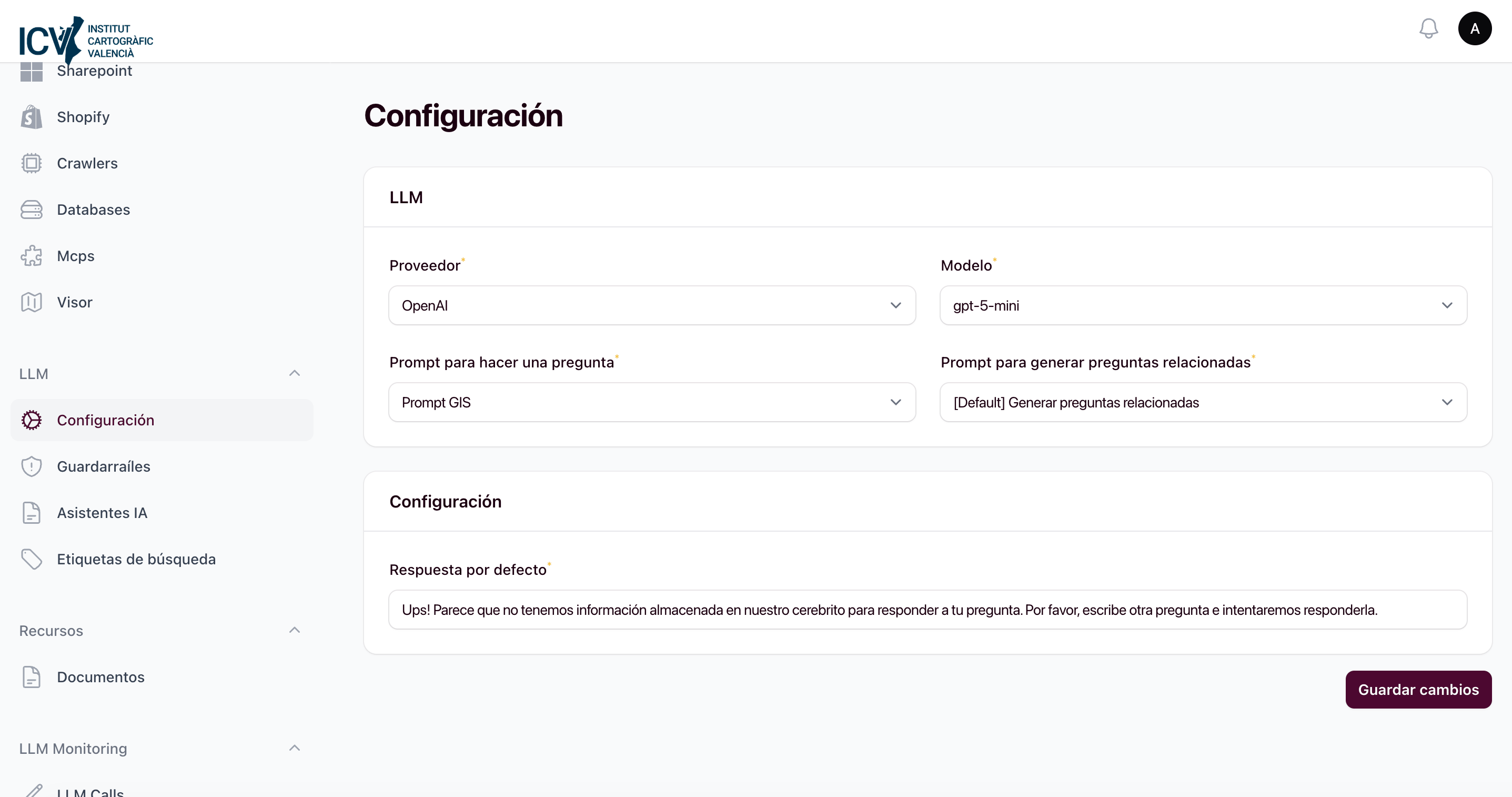
Configuración multimodelo
Selección y configuración de proveedores de LLM por caso de uso
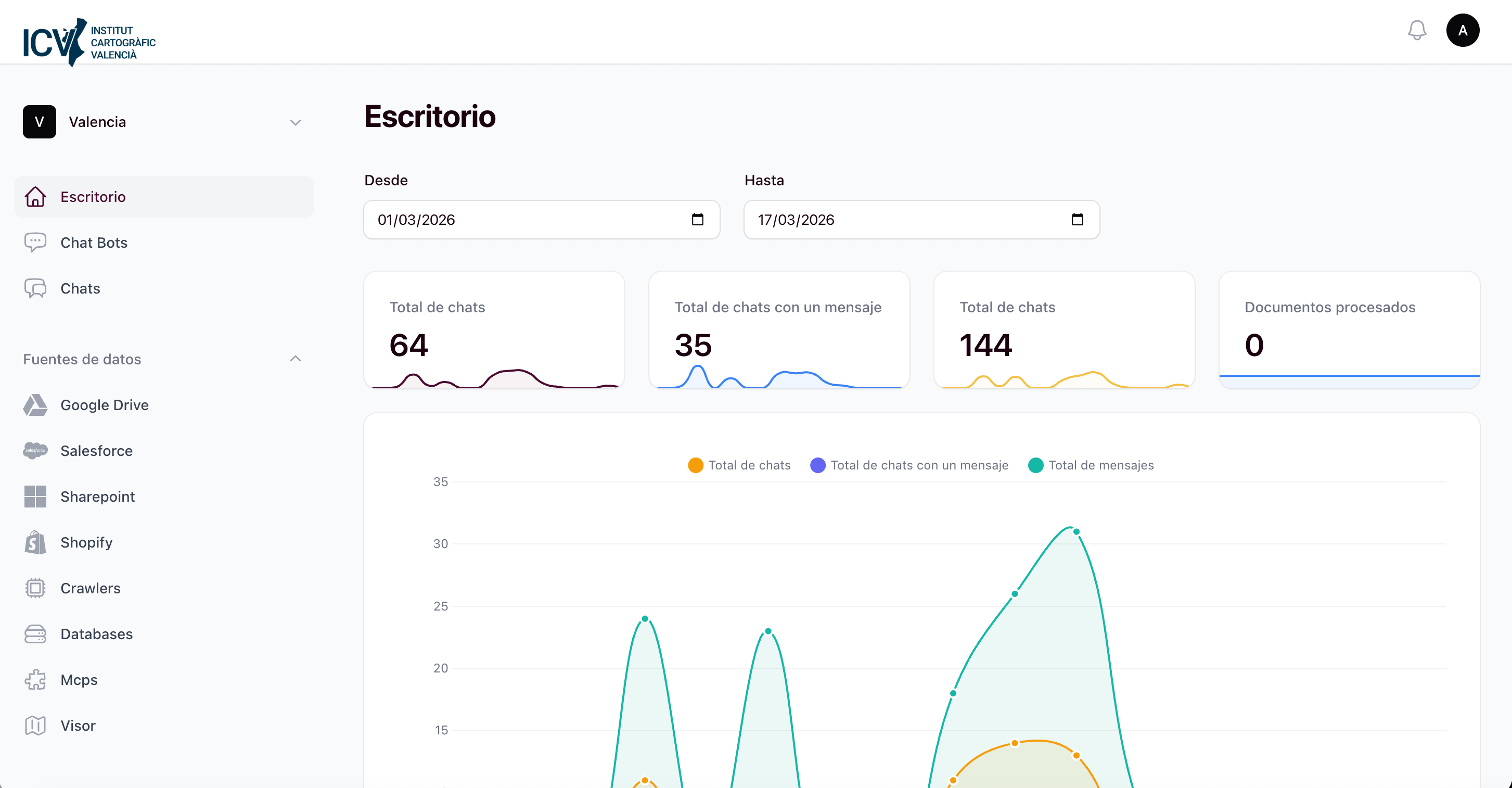
Dashboard de actividad
Monitorización del uso, consultas y calidad de las respuestas
Nuestro enfoque
Construido desde cero, con cada decisión medida
Abordamos el proyecto como producto propio de Borah. MVP rápido para validar la hipótesis central, iteraciones continuas basándose en uso real.
Modelo especializado en PDFs en español
Entrenamos un modelo propio optimizado para leer y comprender documentos PDF en español. No una traducción sobre modelos en inglés, sino un sistema diseñado para ese contexto.
Arquitectura multimodelo
El sistema soporta múltiples proveedores de LLM: OpenAI, Anthropic, modelos open source. Cada empresa elige el modelo que mejor se adapta a su caso de uso y requisitos de privacidad.
Guardrails de ingestión
Sistema de validación automática que controla la calidad de los documentos antes de procesarlos. No todo lo que entra es útil; los guardrails filtran, verifican y aseguran que la base de conocimiento sea fiable.
Ingesta multifuente
Soporte para PDFs, Markdown, Excel, CSV, PowerPoint, URLs con crawler automático, canales de YouTube y vídeos. Una sola plataforma para todo el conocimiento de la empresa, sin importar el formato.
Integración WhatsApp vía Twilio
Los usuarios consultan la base de conocimiento directamente desde WhatsApp. El sistema recibe la pregunta, busca en la documentación de la empresa, y responde con información precisa y contextualizada.
Pipeline de procesamiento
Sistema optimizado de chunking, embeddings y retrieval que conecta las fuentes de datos con los modelos de forma eficiente y precisa.
Stack tecnológico
Resultados
Lo que conseguimos
- Acceso instantáneo a la base documental completa de la empresa, sin búsquedas manuales
- Precisión significativamente mayor en documentos en español frente a herramientas genéricas
- Control total sobre qué datos se ingestan, qué modelos se usan y cómo se procesan las consultas
- Soporte para más de 8 formatos de ingesta distintos, incluyendo vídeo y crawling automático
- Guardrails que garantizan la calidad de la base de conocimiento antes de que llegue al modelo